InfluxDB 性能优化:从配置到客户端,我趟过的坑
前几年搭建了一套轻量级的ELK服务,中间用到了influxdb作为底层存储服务,在遇到InfluxDB写入量大的时候,各种奇怪的性能问题就冒出来了。这篇总结一下我这几年调优 InfluxDB 1.8 的经验,覆盖配置、Telegraf、客户端和运维四个层面,有不少坑是看了日志才找到根因的。
环境说明:本文基于 InfluxDB 1.8,单机部署,数据写入量约 50 万点/秒,CentOS 7 + SSD 硬盘。不同版本或部署方式下,部分参数行为可能略有差异。
一、InfluxDB 配置优化
官方配置文档:https://docs.influxdata.com/influxdb/v1/administration/config/
1. 打开请求日志,方便排查问题
[http]
access-log-path = "/var/log/influxdb/access.log"
开启后记录每个请求的行为,出问题可以直接按状态码筛。未正式上线前可以关掉节省点性能,紧急排查时再开。
配合 logrotate 做日志分割:
/var/log/influxdb/access.log {
daily
rotate 7
compress
delaycompress
missingok
notifempty
postrotate
killall -USR1 influxd 2>/dev/null || true
endscript
}
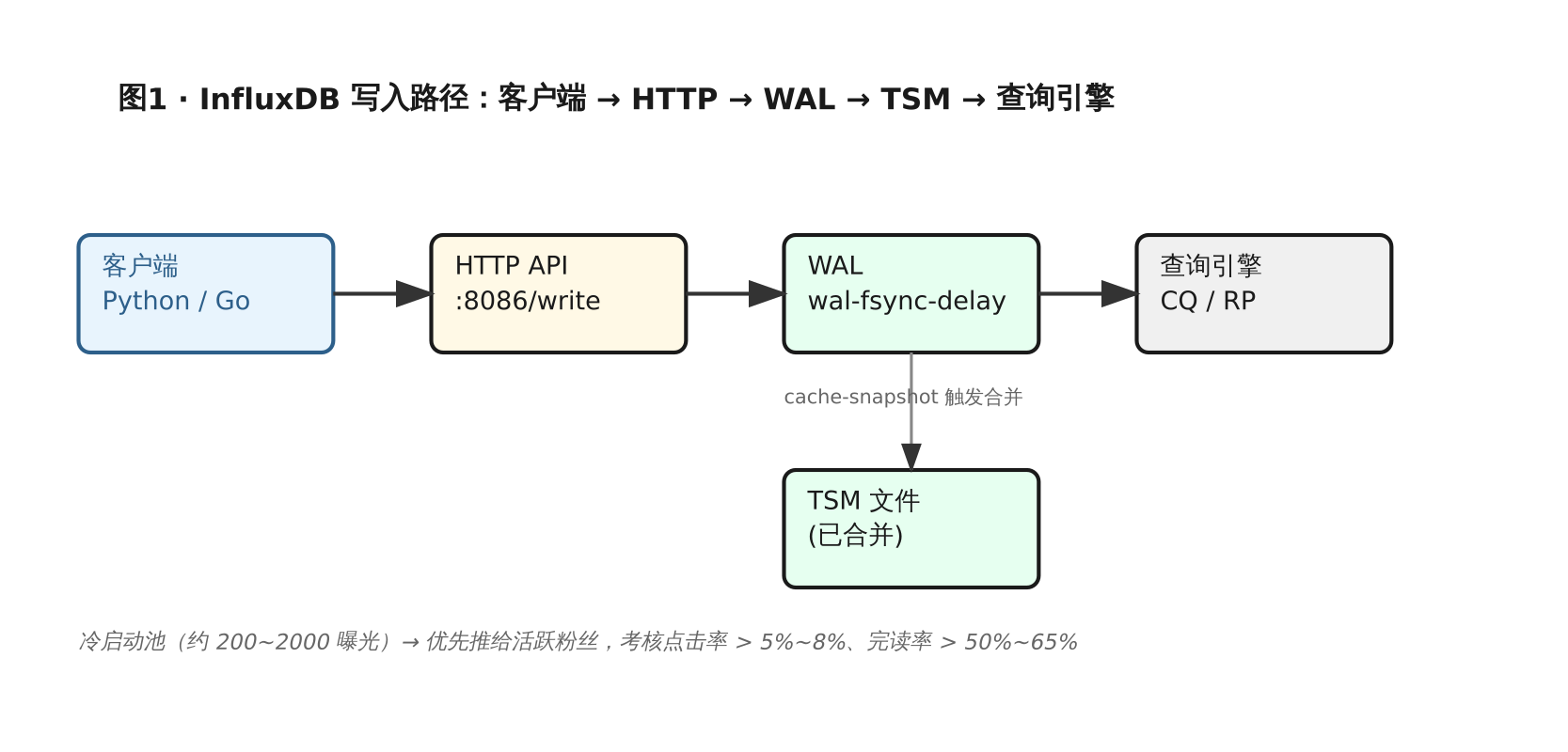
2. wal-fsync-delay:异步化批量写入
[data]
wal-fsync-delay = "10ms"
写 WAL 前先等 10ms,攒一批再刷盘,能显著降低磁盘 IO。实测写入量上来之后这个参数效果最明显。
我的经验:如果磁盘 IO 已经吃紧(比如 %util 经常 80%+),可以适当调高到 20ms~50ms,别一口气设太大,会影响数据一致性。
3. 查询超时:防止连接被拖死
[http]
max-row-iterator-limit = 10000 # 单次查询最多返回行数
max-concurrent-queries = 25 # 最大并发查询数
query-timeout = "30s" # 单次查询超时
read-timeout = "60s"
这个很重要。之前遇到一次前端子查询写得烂,把 influxd 跑满,HTTP 连接全被占住,后面所有写入全部超时。重在预防。
二、InfluxDB 表结构与保存策略
这块是性能的大头,很多问题其实出在设计阶段。
字段类型不能图方便全设 string
时序数据库里 tag、field 的类型直接影响查询效率。string 类型在统计查询时无法参与数值运算,influx 会退化成全表扫描。
| 类型 | 适用场景 | 查询效率 |
|---|---|---|
| float | 传感器数值、指标值 | ✅ 高,可参与运算 |
| integer | 计数、版本号 | ✅ 高 |
| string | 设备名、状态文本 | ⚠️ 只支持等值过滤,不可排序 |
| boolean | 开关状态 | ✅ 高 |
保存策略(Retention Policy)要根据业务来
数据不是越多越好,到期就删,给系统减负。
CREATE RETENTION POLICY "30d_only" ON "mydb"
DURATION 30d REPLICATION 1 SHARD DURATION 1d
Shard Group 合理设置能提升查询效率
shard group 控制数据分片粒度。太大了查询扫的范围大,太小了元数据开销高。
| 数据保留周期 | 建议shard group 时长 |
|---|---|
| ≤7 天 | 1 小时 |
| 7~30 天 | 1 天 |
| 30~365 天 | 7 天 |
| >365 天 | 30 天 |
三、大数据量写入的参数调优
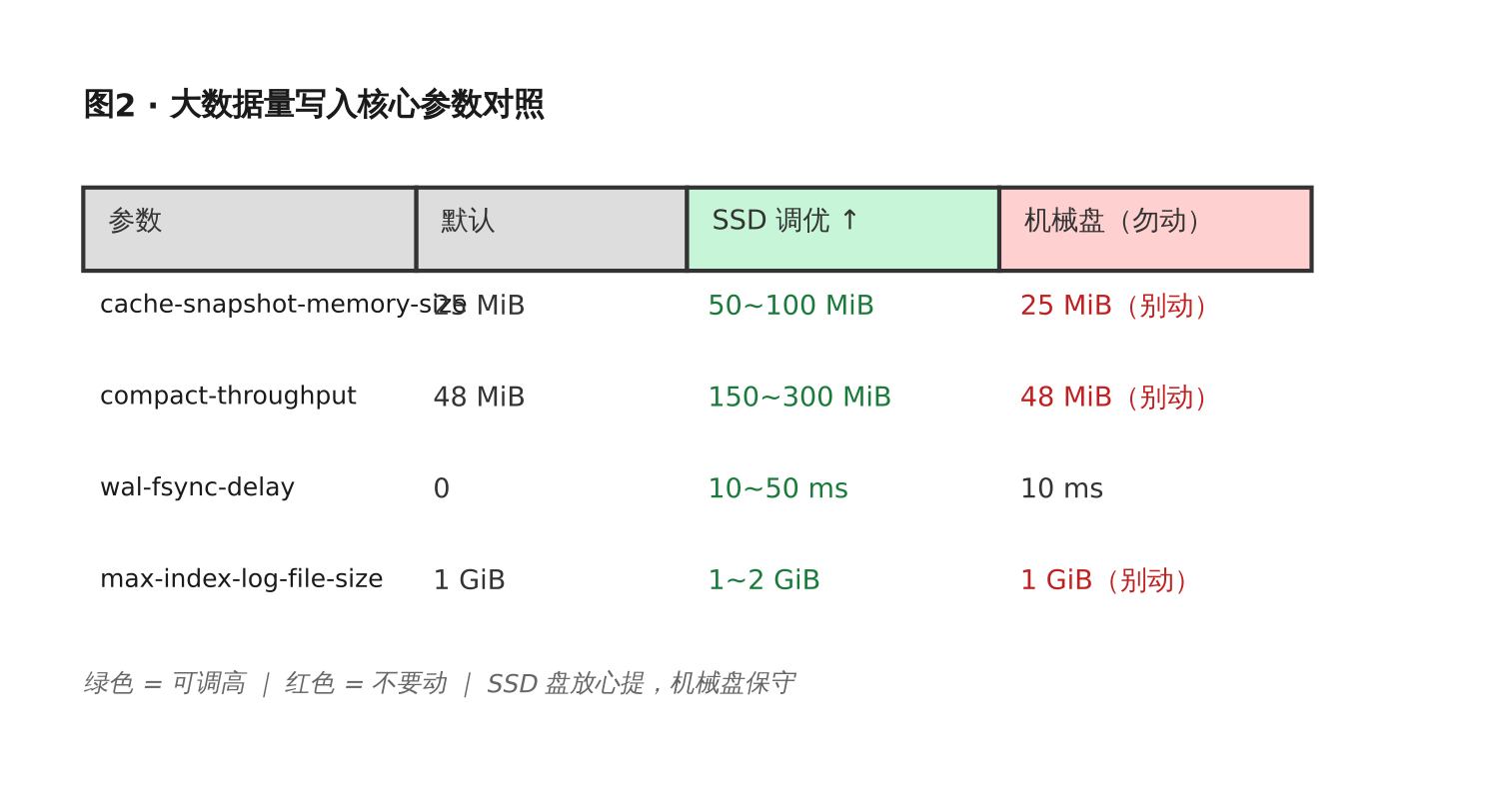
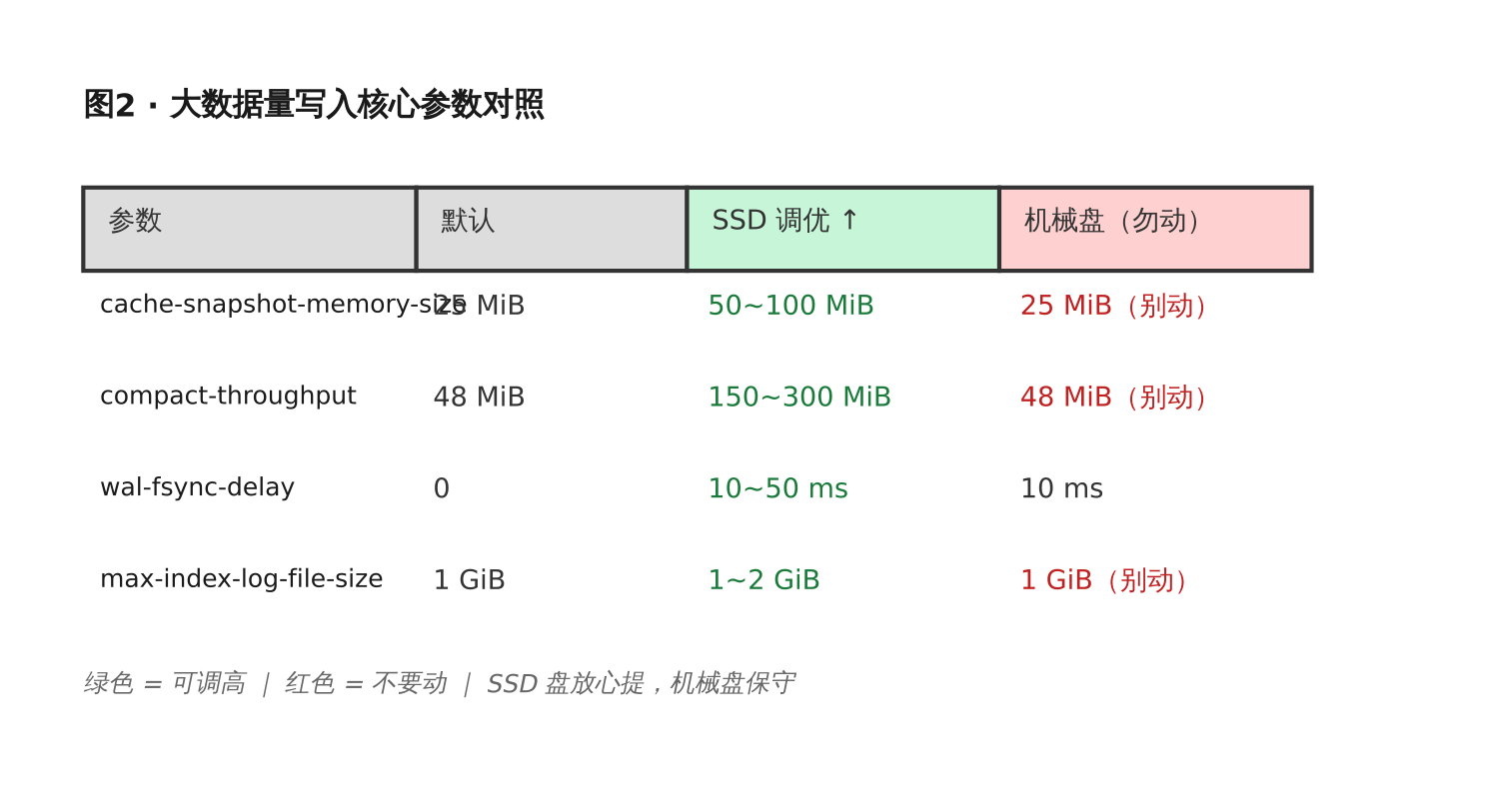
写入量大(>10 万点/秒)的时候,这几个参数要重点看。
cache-snapshot-memory-size
[data]
cache-snapshot-memory-size = "25MiB" # 默认 25M
超过这个阈值,influx 会触发快照写入 TSM 文件。值设高一些能减少 TSM 合并频率,但过高会导致写入峰值时内存压力大。
我的经验:写到 50 万点/秒以上时,调到 50M~100M 比较稳,同时监控 influxd 进程内存别超 70%。compact-throughput / compact-throughput-burst
[data]
compact-throughput = "48MiB" # 默认 48M
compact-throughput-burst = "48MiB"
TSM 文件压缩的后台速率。SSD 盘可以放心往上提,机械硬盘别动,会加剧 IO 争用。
| 硬盘类型 | 建议 compact-throughput |
|---|---|
| SSD | 150M~300M |
| 普通机械盘 | 默认 48M,别动 |
max-index-log-file-size
[data]
max-index-log-file-size = "1GiB" # 默认 1G
这个值直接影响内存 index 的效率。官方建议 1G,官方说可以更高,我没跑过超过 2G 的,供你参考。
四、Telegraf 优化
1. 常用字段标记为 tag,减少查询时的内存拷贝
配置 fields 做 tag 转换:
[[inputs.cpu]]
# 把常用字段标记为 tag,查询时直接过滤
fieldpass = ["usage_idle", "usage_user"]
namepass = ["server01"]
2. 升级 Telegraf 到 1.30
1.30 以上版本对 InfluxDB output 的性能有不少改进,尤其是大批量指标场景下内存占用降了明显。
3. 开启报文压缩
[[outputs.influxdb]]
content-encoding = "gzip" # 1.27+ 支持
写入带宽节省约 60%~70%,CPU 开销增加约 5%,划算。
五、客户端优化
1. 用 msgpack 替代 JSON 序列化
InfluxDB HTTP API 默认返回 JSON,但写入也支持 x-msgpack 格式,体积小解析快:
import msgpack
payload = msgpack.packb({
"name": "sensor_data",
"columns": ["time", "temperature", "humidity"],
"points": [[now, 25.3, 60.1], [now, 26.1, 59.8]]
})
requests.post(
f"http://{INFLUX_HOST}:8086/write?db=mydb",
data=payload,
headers={"Content-Type": "application/x-msgpack"}
)
实测单次请求体积缩小约 5 倍,高并发下 QPS 能提 2~3 倍。
2. 分页查询改用时间戳游标
常规 offset 分页在时序场景下有性能问题,改用时间戳做游标:
def query_by_cursor(last_time, batch_size=10000):
"""基于时间戳的分页,O(1) 复杂度"""
query = f'''
SELECT * FROM sensor_data
WHERE time > {last_time}
ORDER BY time ASC
LIMIT {batch_size}
'''
result = influx_client.query(query)
points = list(result.get_points())
if points:
next_cursor = points[-1]['time']
return points, next_cursor
return points, None
不要用 LIMIT X OFFSET Y 的分页方式,OFFSET 越大越慢,influx 内部要跳过 N 行才能拿到结果。
3. 大批量拉取:用流模式
普通 HTTP 请求会把整个响应加载到内存,拉取几百万点的时候容易 OOM。改用 streaming:
import urllib.request
url = f"http://{INFLUX_HOST}:8086/query?db=mydb&q=SELECT+*+FROM+sensor_data"
req = urllib.request.Request(url)
with urllib.request.urlopen(req) as resp:
# 逐块读取,不一次性加载到内存
for line in resp:
process(line)
六、运维 & Debug
多业务账号隔离
不同业务场景用不同 InfluxDB 账号,好处:
- 权限隔离,互不干扰
- 问题排查时直接定位到业务线
- 方便按账号维度做资源限制
两个有用的 Debug 接口
InfluxDB 自带两个调试端点,生产环境建议按需暴露(注意加防火墙):
# 请求统计(最近 N 秒内的请求量)
curl http://localhost:8086/debug/requests?seconds=10
# 当前系统各项指标(内存、磁盘、查询耗时分布)
curl http://localhost:8086/debug/vars
有问题先看这两个,比猜快多了。
总结:核心优化路径
做了一圈下来,influxDB 性能优化归根结底就是三件事:
- 减少不必要 IO:WAL 异步化、压缩传输、合理 RP 策略
- 让查询走索引:字段类型对、tag vs field 选对、shard group 粒度合理
- 客户端别拖后腿:msgpack、时间戳游标、流式读取
配置改完记得看监控:磁盘 %util、 influxd 进程内存、query 耗时。参数好不好,数据说了算。