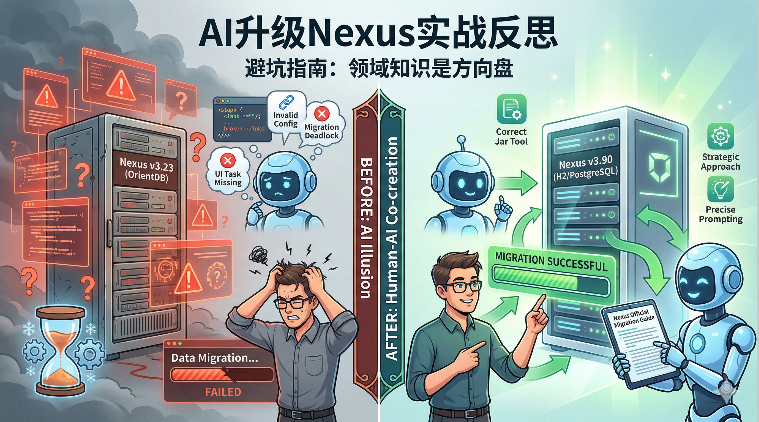
AI避坑指南:通过AI升级Nexus的实战反思
本文复盘了利用 AI 辅助将 Nexus 3.23 升级至 3.90 的实战经历。 由于忽视了底层存储架构(OrientDB 到 H2/PostgreSQL)的断代式变更,盲信 AI 提供的陈旧和错误方案,导致迁移过程遭遇配置无效、任务缺失及僵死等连续“踩坑”。最终通过回归官方文档,精准提问才化险为夷。 总结指出:AI 是加速器,但领域知识是方向盘,使用 AI 需具备鉴别力,不可盲信,应坚持文档先行、实验验证。
背景与挑战
在近期进行的服务器迁移工作中,计划将一台旧服务器上的 Nexus 服务迁移至新环境。由于该服务部署于多年前,版本尚停留在 v3.23,而官方目前已演进至 v3.90。
为了提升迁移效率,我尝试全程通过 Google Gemini 辅助进行版本升级与数据迁移。然而,在执行过程中,AI 提供的方案由于版本特性理解的偏差,导致迁移过程一波三折。
迁移的技术难点
根据分析,Nexus 版本的更迭涉及到了底层存储架构的重大变更:
- 旧版本(v3.70 以前): 默认使用 OrientDB 作为嵌入式数据库。
- 新版本(v3.70 及以后): 官方宣布不再支持 OrientDB,全面转向 H2 或 PostgreSQL。
- 痛点: 这种底层数据库的“断代式”更新,意味着不能通过简单的镜像升级完成,必须经历物理层的数据导出与转换。
踩坑过程
然而,实际执行过程并不顺利,AI 给出的方案接连出现问题:
- UI 任务缺失:按 Gemini 要求下载 3.69 镜像并更新 docker-compose 部署后,我在 UI 控制台中寻找指定的迁移任务,结果根本没发现相关入口。
- 配置无效:继续向 Gemini 提问,它建议修改
nexus.properties文件配置,但修改后依然没有触发预期的迁移任务。 - 文件缺失:再次反馈问题后,Gemini 提供了一条执行内置 Jar 包进行迁移的命令行。但在容器中查找时,发现根本不存在这个 Jar 包。
- 迁移僵死:Gemini 又给出方案,建议通过 JVM 参数触发。日志显示确实开始迁移了,容器中也生成了
.db文件,但进程随后一直等待文件生成完成。 - 确认失败:等待了一两个小时,
nexus.mv.db文件大小一直停留在 9.1M 毫无变化,日志也不再更新。基本可以判定迁移失败。
解决方案
无奈之下,我转到 Nexus 官网查阅升级及数据迁移方案,发现官方明确要求需要下载单独的迁移 Jar 包,通过该工具执行迁移。
整理好已知信息后,我在 Gemini 中重新开启了一个新会话,并提供准确的背景信息让它重新提供方案。这次它的回答准确多了
- 先升级到 Nexus 3.70 版本;
- 从官方下载迁移 Jar 包,执行迁移命令;
- 最后将 Nexus 镜像更新到最新版本。 按此步骤操作,最终顺利完成了迁移。
总结与复盘:如何更好地与 AI 共舞?
这次迁移经历不仅是技术上的填坑,更是对 “如何有效利用 AI” 的一次深度复盘:
- 自我学习是前提:针对不熟悉的领域,自己必须先有一定的掌握。否则当 AI 给出包含误导信息的答案时,很难辨别真伪,容易浪费时间。
- 不可盲信 AI,模型之间交叉验证:不能完全相信 AI 给出的答案。必要时要反复 Check,比如向不同厂商的大模型问同一个问题,对比不同的答复进行验证。
- 精准提问,拒绝泛化:提问时尽量不要泛化,把问题的背景、版本、环境描述得清晰一些,避免 AI“胡思乱想”生成幻觉内容。
感悟: AI 是加速器,但领域知识(Domain Knowledge)是方向盘。独立思考,文档先行,实验验证,依然是系统迁移的三大法宝。